Постановка задачи
Пусть дана строка, содержащая арифметическое выражение.
Для того, чтобы примеры алгоритмов не обрастали техническими подробностями, будем считать, что
- все числа целые, без знака (то есть в строке нет унарных плюсов или минусов, знаки плюс и минус означают только операции);
- в строке нет никаких других знаков, кроме цифр, круглых скобок и знаков арифметических действий. По ходу написания примеров будут даны комментарии и советы в каком месте алгоритма лучше (по мнению автора) делать проверки на корректность данных, но сильно отклоняться от темы не будем;
- круглые скобки расставлены корректно (между скобками есть хотя бы одно число);
Примером такого выражения будет:
Идея решения
Разделим выражение на минимальные блоки — лексемы.
Лексема — это некоторый наименьший набор символов, который имеет законченный смысл в рамках данного выражения.
В такой постановке задачи лексемами будут:
- знаки арифметических действий;
- открывающаяся скобка;
- закрывающаяся скобка;
- числа (обратите внимание, что отдельные цифры законченного смысла не имеют; когда мы сами читаем выражение, нас интересуют только числа целиком);
- конец выражения (строки)
- неизвестная лексема (это состояние можно будет передавать другим частям алгоритма, если в строке встретился некорректный символ; этот вид лексем, как мы уже предупреждали, не будет встречаться в примерах реализации);
На рисунке разными цветами показаны разные типы лексем, из которых состоит арифметическое выражение.
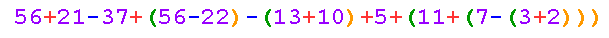
Будем рассматривать лексемы строки последовательно, слева направо.
В первом приближении алгоритм будет выглядеть так:
- Возьмем первую лексему. Если это число, то запомним его в специальной переменной «текущий результат».
- Цикл: пока текущая лексема не является концом выражения:
- Возьмем лексему
- Обработаем лексему, если нужно, то исправим «текущий результат»
- Вернем «текущий результат» в качестве ответа.
Из этого краткого описания видно, что алгоритм можно разбить на следующий подзадачи:
- получение следующей лексемы и размещение ее в специально для этого созданной переменной;
- обработка лексем каждого вида
- для арифметических операций
- для скобок
Также для работы алгоритма нам понадобятся следующие данные:
current_position – номер первого еще не рассмотренного символа строки.
current_lexem_type – тип лексемы, которую в данный момент анализирует алгоритм.
Типы могут быть:
- LT_END– конец выражения;
- LT_OPEN– открывающаяся скобка;
- LT_CLOSE– закрывающаяся скобка;
- LT_NUMBER– число;
- LT_PLUS– знак плюс;
- LT_MINUS– знак минус;
- LT_MUL– знак умножения;
- LT_DIV– знак деления;
В случае, если текущая лексема является числом, то понадобится также значение этого числа. Для этого заведем переменную:current_lexem_value
Для хранения промежуточного результата (накопленного к текущему моменту; того, который вычислен в результате анализа уже просмотренной части строки) заведем переменную current_result
Эта переменная, в отличие от остальных, будет не глобальной, а локальной в одной из функций.
Далее будем называть функции, отвечающие за разные части работы следующими именами:
Обратите внимание, что часть выражения, заключенная в скобки, также является выражением. Поэтому ее вычисление аналогично вычислению всего выражения (можно сделать рекурсивный вызов функции).
Функции обработки лексем далее будем называть:
- calc_plus(– функция обработки знака плюс;
- calc_minus()- функция обработки знака плюс;
- calc_mul()- функция обработки знака умножения;
- calc_div()- функция обработки знака деления;
- calc_brackets()- функция обработки скобок;
Теперь можно переписать «план» программы таким образом:
- прочитать строку (S), содержащую выражение;
- current_position = 1 (будем считать, что символы строки нумеруются с 1);
- current_result = 0
- result = evaluate_expression()
- вывод result
Как устроено большинство из перечисленных функций рассмотрим далее на примерах.