Задача №113222. Расшифровка ДНК
Это интерактивная задача.
При проведении раскопок на территории Республики Татарстан были обнаружены останки неизвестного древнего животного, обитавшего в окрестностях современной Казани миллионы лет назад. Как и у всех живых организмов, молекула его ДНК представляет собой последовательность из n нуклеотидов, однако число встречающихся в ней различных нуклеотидов может отличаться от современных организмов.
Для изучения находки был создан специальный прибор, который может просканировать последовательный участок нуклеотидов в ДНК и вычислить, сколько различных видов нуклеотидов содержится на нём. К сожалению, молекула ДНК может выдержать не более \(q\) операций сканирования, после чего разрушается.
Исследователи хотят с помощью этого прибора найти \(k\) — количество различных нуклеотидов в ДНК, и определить позиции, в которых в ДНК находятся одинаковые нуклеотиды. Ученые хотят закодировать последовательность нуклеотидов в молекуле последовательностью целых положительных чисел \(a_1, a_2, \dots, a_n (1 \le a_i \le k)\), таких что одинаковые числа кодируют одинаковые нуклеотиды, а различные числа — различные нуклеотиды.
Требуется написать программу, которая, взаимодействуя с программой жюри, определит количество различных нуклеотидов в последовательности, а также числовую последовательность, кодирующую последовательность нуклеотидов в молекуле ДНК.
При запуске решения на вход подается целое число \(n\) — длина молекулы ДНК (\(1 \le n \le 3 000\)).
Для каждого теста зафиксированы числа \(k\) — количество различных нуклеотидов (\(1 \le k \le n\)) и \(q\) — максимальное количество запросов. Гарантируется, что \(q\) запросов достаточно, чтобы решить задачу. Эти числа не сообщаются программе участника, но ограничения на эти числа в различных подзадачах приведены в таблице системы оценивания. Если программа участника делает более \(q\) запросов программе жюри, на этом тесте она получает в качестве результата тестирования «Неверный ответ».
Чтобы сделать запрос, следует вывести строку «? i j», где \(i\) и \(j\) — целые положительные числа, номера первого и последнего нуклеотида непрерывного участка молекулы ДНК, для которого требуется узнать число различных нуклеотидов в нём (\(1 \le i \le j \le n\)).
В ответ на каждый запрос программа получает целое число \(p\) — количество различных нуклеотидов в фрагменте ДНК, указанном в запросе.
Если программа определила ответ на задачу, то она должна вывести три строки. Первая строка должна содержать слово «Ready!». Вторая строка должна содержать целое число \(k\) — количество различных нуклеотидов в молекуле. Третья строка должна содержать последовательность \(n\) целых чисел, разделенных пробелами: \(a_1, a_2, \dots, a_n\) — коды нуклеотидов \((1 \le a_i \le k)\). Если подходящих последовательностей несколько, то допускается вывести любую из них.
После этого программа должна завершиться.
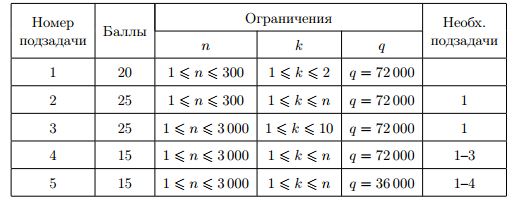
В первом примере \(n = 2\), за один запрос можно определить, равны ли первый и второй нуклеотид друг другу.
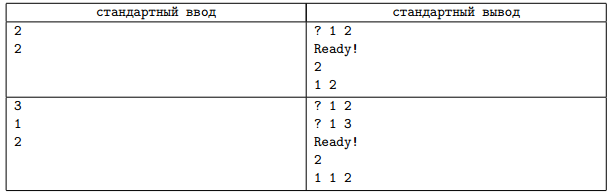
В втором примере \(n = 3\), результат первого запроса показывает, что первые два нуклеотида одинаковые, результат второго запроса позволяет сделать вывод о том, что третий нуклеотид от них отличается. В этом случае допустимы два варианта ответа: 1 1 2 и 2 2 1.
В точности соблюдайте формат выходных данных. После каждого вывода обязательно выводите один перевод строки и сбрасывайте буфер вывода — для этого используйте flush(output) на языке Паскаль или Delphi, fflush(stdout) или cout.flush() в C/C++, sys.stdout.flush() на языке Python, System.out.flush() на языке Java.