Задача №114132. Поиск идеи
3019 год. При раскопках древнего города Иннополис археологи обнаружили артефакт — жёсткий диск, на котором находится файл, предположительно содержащий тексты всех задач всероссийских олимпиад по информатике.
После исследования файла было выяснено, что информация в нём закодирована таким образом, что записанный в файле текст представляет собой строку \(t\) из букв английского алфавита. Текст с задачами оказался довольно длинным и содержал много повторений, поэтому файл хранился на диске в сжатом виде. Для его распаковки используется следующий алгоритм.
В процессе распаковки формируется строка \(t\) из строчных букв английского алфавита. Исходно строка пуста. Сжатый файл состоит из \(n\) блоков, которые должны быть обработаны в порядке следования. Каждый блок имеет один из двух типов.
- Блок « 1 \(w\) », где \(w\) — строка. При обработке такого блока в конец строки \(t\) дописывается строка \(w\).
- Блок « 2 \(pos\) \(len\) », где \(pos\) и \(len\) — положительные целые числа. Пусть символы строки \(t\) пронумерованы с \(1\). При обработке такого блока в конец строки \(t\) по очереди приписываются \(len\) подряд идущих символов строки \(t\), начиная с позиции \(pos\). При этом, если значение \(len\) достаточно велико, некоторые только что выписанные символы могут быть снова использованы при обработке того же блока.
Ученые решили выяснить, сколько раз некоторая идея встречалась в олимпиадах. Для этого они сформировали строку \(p\) из строчных букв английского алфавита и хотят найти количество вхождений строки \(p\) как подстроки в полученную после распаковки файла строку \(t\).
Строка \(p\) длины \(m\) входит в строку \(t\) как подстрока с позиции \(i\), если \(m\) следующих подряд символов строки \(t\), начиная с \(i\)-го, представляют собой строку \(p\). Например, строка « aba » входит как подстрока в строку « ababaaba » три раза: с позиций 1, 3 и 6.
Требуется написать программу, которая определяет количество вхождений заданной строки \(p\) в полученную после распаковки файла строку \(t\).
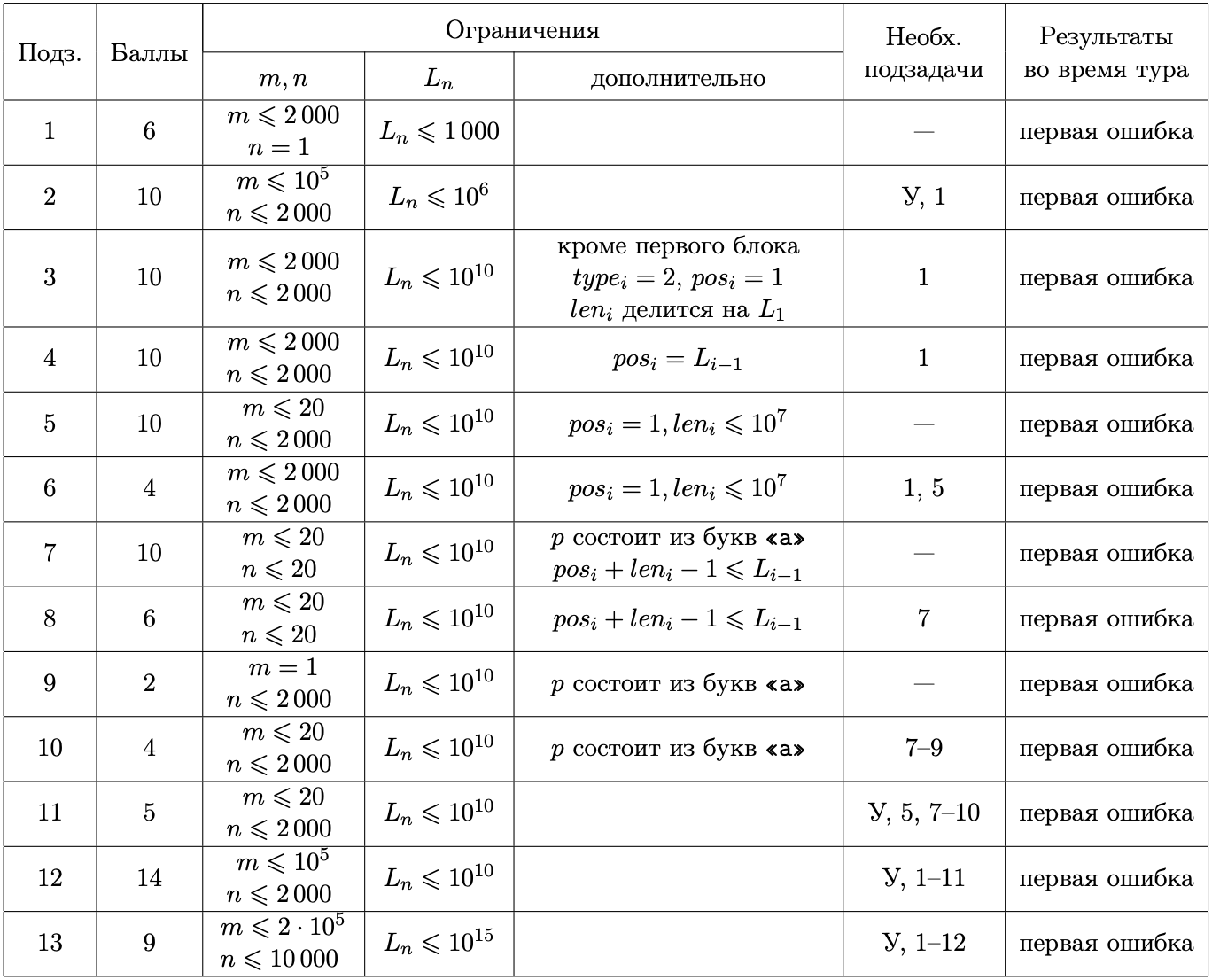
В первой строке находятся натуральные числа \(m\) и \(n\) — длина строки \(p\) и количество блоков в сжатом тексте (\(1 \le m \le 2 \cdot 10^5\), \(1 \le n \le 10^4\)).
Во второй строке входных данных задана непустая строка \(p\), состоящая из строчных букв английского алфавита.
В следующих \(n\) строках находятся описания блоков в описанном в условии формате. Для блоков первого типа приписываемая строка \(w\) непуста, сумма длин всех строк \(w\) в блоках первого типа не превышает \(2 \cdot 10^5\). Для блоков второго типа в строке \(t\) к моменту обработки этого блока находится не менее \(pos\) символов. Длина распакованного текста не превышает \(10^{15}\) символов.
Выведите одно целое число — количество вхождений строки \(p\) в текст.
Обозначим длину текста \(t\) после обработки \(i\) блоков как \(L_i\).
Обозначим тип \(i\)-го блока как \(type_i\). Если \(type_i = 2\), то обозначим параметры этого блока как \(pos_i\) и \(len_i\).
3 4 aba 1 ab 2 1 3 2 3 3 2 1 8
6