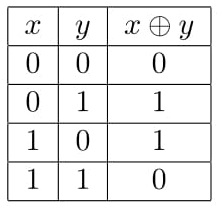
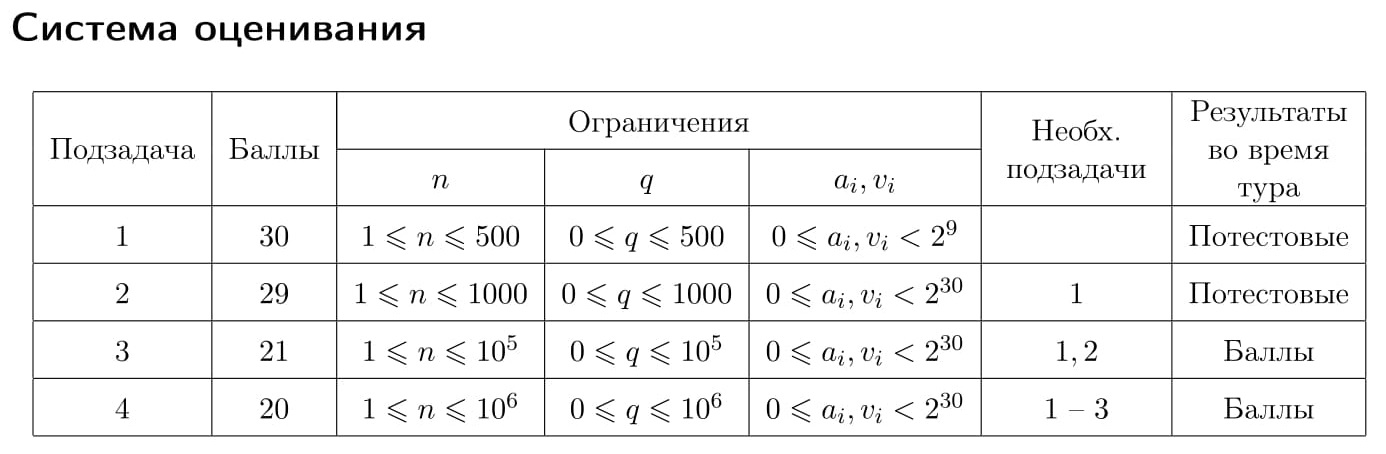
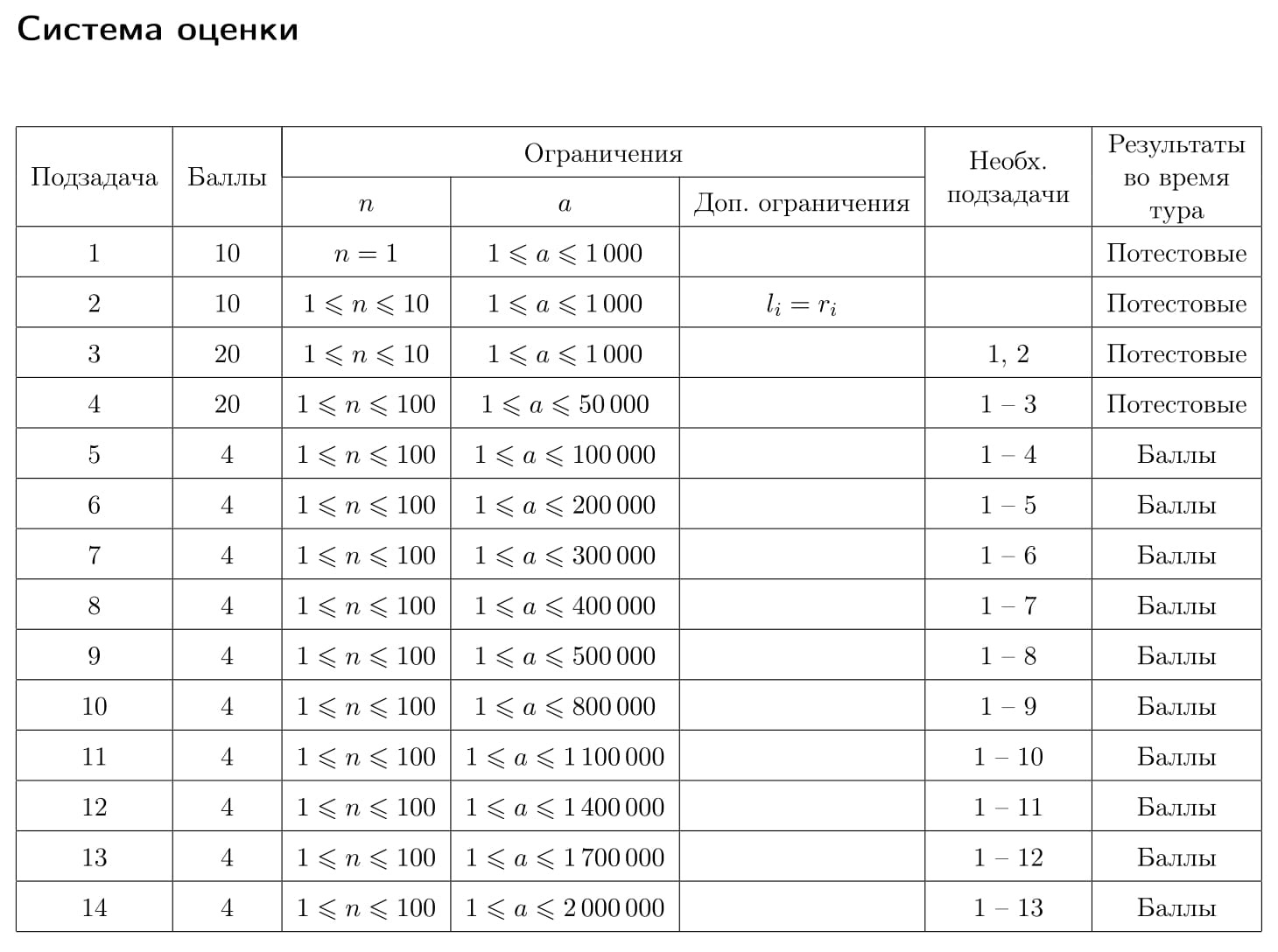
--->
24 задач
<---
Источники
-->
Личные олимпиады
Олимпиады сайта(17 задач)
Школьная личная олимпиада ФМШ №2007 г. Москвы(7 задач)
Золотая середина (Новосибирск)(10 задач)
Нижегородская олимпиада школьников(42 задач)
Московская олимпиада школьников(168 задач)
Индивидуальная олимпиада по информатике и программированию (ИОИП)(22 задач)
Открытая олимпиада школьников(173 задач)
Украинские олимпиады(61 задач)
Республиканская олимпиада школьников (Беларусь)(6 задач)
Жаутыковские олимпиады(8 задач)
Всероссийская олимпиада школьников(304 задач)
Международные олимпиады(32 задач)
Central European Olympiad in Informatics (4 задач)
Интернет-олимпиады(2 задач)
COCI(36 задач)
Турнир Архимеда(36 задач)
Baltic Olympiad in Informatics(10 задач)
Школьная личная олимпиада ФМШ №2007 г. Москвы(7 задач)
Золотая середина (Новосибирск)(10 задач)
Нижегородская олимпиада школьников(42 задач)
Московская олимпиада школьников(168 задач)
Индивидуальная олимпиада по информатике и программированию (ИОИП)(22 задач)
Открытая олимпиада школьников(173 задач)
Украинские олимпиады(61 задач)
Республиканская олимпиада школьников (Беларусь)(6 задач)
Жаутыковские олимпиады(8 задач)
Всероссийская олимпиада школьников(304 задач)
Международные олимпиады(32 задач)
Central European Olympiad in Informatics (4 задач)
Интернет-олимпиады(2 задач)
COCI(36 задач)
Турнир Архимеда(36 задач)
Baltic Olympiad in Informatics(10 задач)