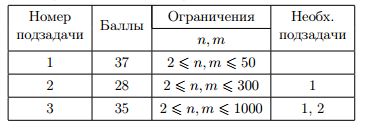
В корпорации работают \(n\) сотрудников, один из которых является директором. У каждого сотрудника, кроме директора, имеется ровно один непосредственный руководитель.
Каждый сотрудник выполняет свою строго определённую работу. Если сотруднику a требуется выполнить работу, которой занимается сотрудник \(b\), то он должен отправить сотруднику \(b\) заявку. Согласно корпоративной политике напрямую заявки могут передаваться
только либо от сотрудника его непосредственному руководителю, либо наоборот — от руководителя к непосредственному подчинённому. Заявка передается от сотрудника к сотруднику до тех пор, пока не достигнет сотрудника \(b\).
Чтобы разгрузить сотрудников, корпорация наняла \(k\) курьеров. Курьер с номером \(i\) закреплён за парой сотрудников \(a_i\) и \(b_i\) и занимается доставкой заявок между ними. Если одному сотруднику из этой пары требуется передать заявку другому, то
он отдает заявку курьеру, который последовательно передает заявку между сотрудниками в соответствии с корпоративной политикой, пока заявка не пройдет всех необходимых промежуточных сотрудников и окажется доставленной адресату. В процессе доставки
одной заявки курьер не посещает одного и того же сотрудника более одного раза.
С целью оптимизации расходов решено найти пару курьеров, пути следования которых перекрываются наиболее сильно, и отказаться от услуг одного из них, поручив его работу второму. Назовём
степенью дублирования для пары курьеров количество переходов между сотрудником и его непосредственным начальником в любом направлении, входящих в путь как первого, так и второго курьера.
Требуется написать программу, которая определит двух курьеров с наибольшей степенью дублирования.
Выходные данные
Первая строка выходных данных должна содержать единственное целое число — наибольшую степень дублирования двух курьеров.
Вторая строка выходных данных должна содержать два различных целых числа от 1 до \(k\) — номера курьеров, входящих в пару с наибольшей степенью дублирования. Если таких пар несколько, можно вывести любую из них.
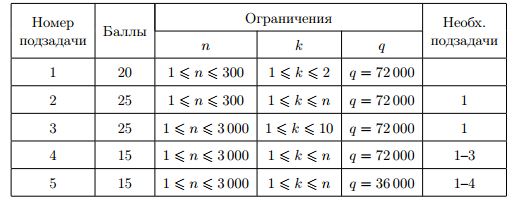
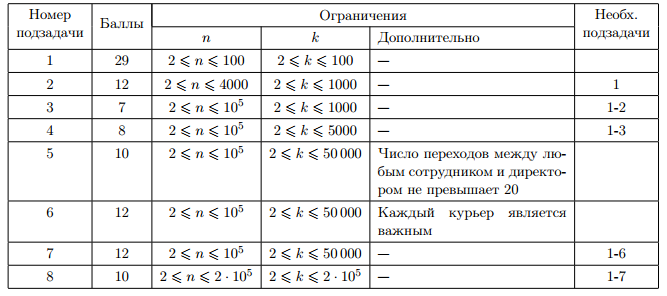
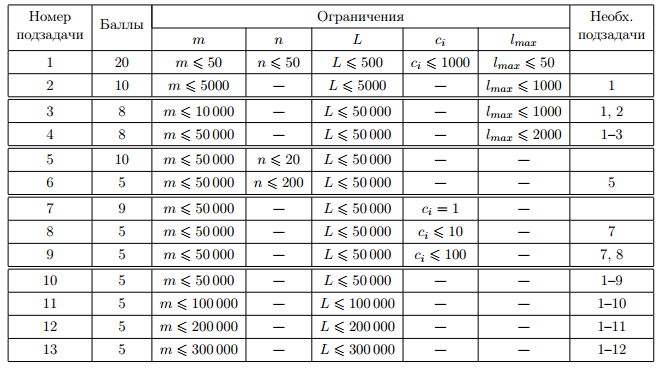
Таблица системы оценивания
Замечание
Будем говорить, что сотрудник \(a\) подчиняется приказам сотрудника \(b\), если \(b\) является непосредственным начальником \(a\), или же непосредственный начальник \(a\) подчиняется приказам сотрудника \(b\). Естественно называть важным курьера, передающего
заявки от сотрудника к кому-либо, кто подчиняется его приказам (или в обратном направлении).
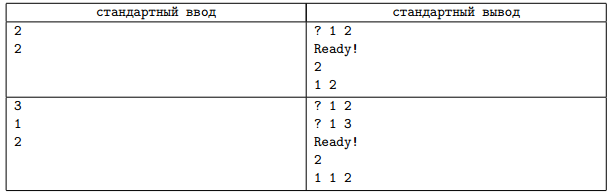
Пояснения к примерам
В первом примере имеется два курьера. Первый курьер доставляет завки от сотрудника 1 сотруднику 3 или обратно. Так, доставляя завку от сотрудника 1 к сотруднику 3, он сначала передает заявку от сотрудника 1 сотруднику 2, а затем от сотрудника 2 сотруднику
3. Второй курьер доставляет завки от сотрудника 1 сотруднику 4 или обратно. Например, доставляя заявку от сотрудника 4 сотруднику 1, он сначала передаёт её от сотрудника 4 сотруднику 2, а затем от сотрудника 2 сотруднику 1. Степень дублирования
этой пары курьеров равна 1, так как для них общим является переход между сотрудником 1 (директором) и сотрудником 2.
Во втором примере также имеется два курьера, но их пути не пересекаются.
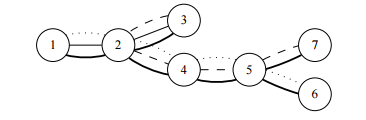
Третий пример изображён на рисунке выше. Жирными линиями обозначены переходы между сотрудниками. Тонкими линиями обозначен путь первого курьера между сотрудниками 1 и 3. Длинным пунктиром обозначен путь второго курьера между сотрудниками 3 и 7. Коротким
пунктиром обозначен путь третьего курьера между сотрудниками 1 и 6.
В пути первого и второго курьера одновременно входит только переход между сотрудниками 2 и 3. В пути первого и третьего курьера одновременно входит только переход между сотрудниками 1 и 2. В пути второго и третьего курьера одновременно входят два перехода:
между сотрудниками 2 и 4 и между сотрудниками 4 и 5. Таким образом, пара из курьеров с номерами 2 и 3 имеет наибольшую степень дублирования, равную 2.
В четвертом примере все курьеры переносят заявки между директором и сотрудником номер 4. Таким образом, все пары курьеров имеют степень дублирования равную 3. Разрешается вывести любую пару.