История Татаро-монгольского ханства богата на правителей. Каждый из N правителей принадлежал к одной из двух династий, причём власть часто переходила от одной династии к другой. Каждое восхождение правителя на престол отмечалось праздником, проводимым 26 марта. В летописях зафиксированы годы проведения этих праздников, причем известно, что правители первой династии устраивали для народа праздник кумыса, а второй — праздник мёда.
На конференции по истории Татаро-монгольского ханства каждый из S учёных предложил свою версию толкования летописи. А именно, i-й историк утверждал, что от каждого праздника кумыса до следующего праздника кумыса проходило не менее KLi лет, но не более KRi лет, в то время как от каждого праздника мёда до следующего праздника мёда проходило не менее MLi лет, но не более MRi лет.
Каждой предложенной версии может соответствовать несколько распределений правителей по династиям. Ученые договорились считать показателем сомнительности распределения число переходов власти к представителю той же самой династии.
Требуется написать программу, которая найдёт распределение, соответствующее хотя бы одной из версий и имеющее наименьший показатель сомнительности, а также версию, которой оно соответствует.
Выходные данные
Первая строка выходного файла должна содержать числа P и Q, где P — номер учёного, версии которого соответствует распределение с наименьшим показателем сомнительности, а Q — показатель сомнительности этого распределения.
Вторая строка должна состоять из N цифр 1 и 2, записанных без пробелов, означающих приход к власти представителя первой или второй династии соответственно. Если существует несколько решений с наименьшим показателем сомнительности Q, выведите любое из них.
В случае, если ни в одной из версий учёных не существует способа распределения периодов правления между династиями так, чтобы не нарушались ограничения на промежутки времени между праздниками, выходной файл должен содержать единственное число 0.
Примечание
Данная задача содержит шесть подзадач. Для оценки каждой подзадачи используется своя группа тестов. Баллы за подзадачу начисляются только в том случае, если все тесты из этой группы пройдены.
- Тесты из условия. Подзадача оценивается в 0 баллов.
- 2 ≤ N ≤ 15, 1 ≤ S ≤ 10. Подзадача оценивается в 20 баллов.
- 2 ≤ N ≤ 2000, 1 ≤ S ≤ 50, N × S ≤ 2000. Подзадача оценивается в 20 баллов.
- 2 ≤ N ≤ 10 000, 1 ≤ S ≤ 50, N × S ≤ 10 000. Подзадача оценивается в 20 баллов.
- 2 ≤ N ≤ 200 000, 1 ≤ S ≤ 50, N × S ≤ 200 000. Подзадача оценивается в 20 баллов.
- 2 ≤ N ≤ 200 000, 1 ≤ S ≤ 50. Подзадача оценивается в 20 баллов.
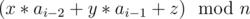 . Первый запрос имеет вид {
. Первый запрос имеет вид {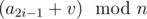 ,
,