--->
90 задач
<---
Источники
Известно, что если сохранить в каждом слове текста первую и последнюю букву, а остальные переставить произвольным образом, получившийся текст по-прежнему можно достаточно свободно прочитать. В лаборатории информатики исследуют аналогичный феномен для числовых последовательностей.
Будем называть последовательность, состоящую из целых положительных чисел, корректной , если первое число в этой последовательности является минимальным, а последнее — максимальным. Например, последовательности [1, 3, 2, 4] и [1, 2, 1, 2] являются корректными, а последовательность [1, 3, 2] — нет.
Задана последовательность [ a 1 , a 2 , ..., a n ] . Будем называть отрезок элементов заданной последовательности [ a l , a l + 1 , ..., a r ] корректным, если он представляет собой корректную последовательность: a l является минимальным числом на этом отрезке, а a r — максимальным.
В рамках исследования необходимо разбить заданную последовательность на минимальное количество непересекающихся корректных отрезков. Например, последовательность [2, 3, 1, 1, 5, 1] можно разбить на три корректных отрезка: [2, 3] и [1, 1, 5] и [1] .
Требуется написать программу, которая по заданной последовательности определяет, на какое минимальное количество корректных отрезков её можно разбить.
Первая строка входных данных содержит целое число n ( 1 ≤ n ≤ 300 000 ) — количество элементов в заданной последовательности.
Вторая строка содержит n целых чисел a 1 , a 2 , ..., a n — заданную последовательность ( 1 ≤ a i ≤ 10 9 ).
Выведите одно число — минимальное количество корректных отрезков, на которое можно разбить заданную последовательность.
5 5 4 3 2 1
5
4 1 3 2 4
1
6 2 3 1 1 5 1
3
Скажем, что последовательность строк t 1 , ..., t k является путешествием длины k , если для всех i > 1 t i является подстрокой t i - 1 строго меньшей длины. Например, { ab , b } является путешествием, а { ab , c } или { a , a } — нет.
Определим путешествие по строке s как путешествие t 1 , ..., t k , все строки которого могут быть вложены в s так, чтобы существовали (возможно, пустые) строки u 1 , ..., u k + 1 , такие, что s = u 1 t 1 u 2 t 2 ... u k t k u k + 1 . К примеру, { ab , b } является путешествием по строке для abb , но не для bab , так как соответствующие подстроки расположены справа налево.
Назовём длиной путешествия количество строк, из которых оно состоит. Определите максимально возможную длину путешествия по заданной строке s .
В первой строке задано целое число n ( 1 ≤ n ≤ 500 000 ) — длина строки s .
Во второй строке содержится строка s , состоящая из n строчных английских букв.
Выведите одно число — наибольшую длину путешествия по строке s .
В первом примере путешествием по строке наибольшей длины является { abcd , bc , c } .
Во втором примере подходящим вариантом будет { bb , b } .
7 abcdbcc
3
4 bbcb
2
Назовем подпоследовательностью массива \(a\) непустой массив \(b\) такой, что он может быть получен из массива \(a\) удалением нескольких (возможно, никаких) элементов массива \(a\). Например, массив \([1, 3]\) является попоследовательностью массива \([1, 2, 3]\), но \([3, 1]\) не является.
Назовем подотрезком массива \(a\) непустой массив \(b\) такой, что он может быть получен путем удаления нескольких (возможно, никаких) первых и последних элементов массива \(a\). Например, \([1, 2]\) является подотрезком массива \([1, 2, 3]\), а \([1, 3]\) не является. Несложно заметить, что у массива длины \(n\) ровно \(\frac{n(n + 1)}{2}\) подотрезков.
Назовем массив \(a\) длины \(n\) возрастающим , если для любого \(1 \leq i < n\) выполняется \(a_i < a_{i + 1}\).
Монотонностью массива назовем количество его возрастающих подотрезков.
Дан массив \(a\) длины \(n\). Посчитайте сумму монотонностей по всем его подпоследовательностям. Так как ответ может быть очень большим, выведите его по модулю \(10^9 + 7\).
В первой строке задано целое число \(n\) (\(1 \leq n \leq 200\,000\)) — длина массива \(a\).
Во второй строке заданы \(n\) целых чисел (\(1 \leq a_i \leq 200\,000\)) — элементы массива \(a\).
Выведите одно целое число — сумму монотонностей всех подпоследовательностей по модулю \(10^9 + 7\).
В первом тестовом примере у массива есть \(7\) подпоследовательностей:
Во втором тестовом примере все возрастающие подотрезки всех подпоследовательностей имеют длину \(1\).
3 1 3 2
15
3 6 6 6
12
Фермер Джон спрятал ключи от трактора в сейфе. Коровы пытаются взломать этот сейф. Сейф защищён сложной парольной системой.
Она организована как подвешенное за вершину 0 дерево из \(n\) (\(1 \le n \le 20000\)) вершин, каждая из которых требует цифру от \(0\) до \(9\). Вершины пронумерованы от \(0\) до \(n - 1\).
Единственная информация, которой владеют коровы – что определённые последовательности длины \(5\) не появляютя на путях в этом дереве начиная с каких-то стартовых позиций при движении вверх по дереву.
По заданным \(m\) (\(0 \le m \le 50000\)) последовательностям длины \(5\), вместе с их стартовой позицией в дереве помогите коровам вычислить сколько паролей будет не подходить.
Вы должны выводить свой ответ по модулю \(1234567\).
Первая строка ввода содержит два разделённых пробелом целых числа, \(n\) и \(m\) (\(1 \le n \le 20000, 0 \le m \le 50000\)) - количество вершин в дереве и количество запрещённых последовательностей соответственно.
В последующих \(i\) строках находится описание дерева. Строка \(i + 1\) содержит одно целое число \(p[i]\), означающее родителя вершины \(i\) в дереве (\(0 \le p[i] \lt i\)).
В последующих \(m\) строках находится описание запрещённых последовательностей. Строка \(n + i\) содержит два целых числа \(v_i\) и \(s_i\), разделенные пробелом - стартовую вершину последовательности, и строку из \(5\) цифр, которая не встретится в шифре начиная с вершины \(v_i\) если двигаться вверх по дереву (\(0 \le v_i \lt n\)) соответственно.
Гарантируется, что корень дерева находится не менее чем в 4 шагах от \(v_i\).
Выведите единственное целое число – количество неподходящих конфигураций цифр по модулю \(1234567\).
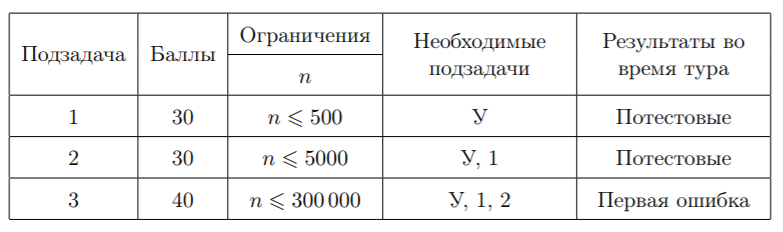
Подзадача 1 (10 баллов): \(1 \le n \le 15, 0 \le m \le 15\)
Подзадача 2 (15 баллов): \(1 \le n \le 1000, 0 \le m \le 2000\)
Подзадача 3 (20 баллов): \(1 \le n \le 1000, 0 \le m \le 50000\)
Подзадача 4 (55 баллов): \(1 \le n \le 20000, 0 \le m \le 50000\)
6 2 0 1 2 3 3 4 01234 5 91234
19
Легенда этой задачи слишком велика, чтобы она уместилась на этой странице, поэтому ее здесь не будет.
Вам дан массив \(V\) длины \(n\), и вы хотите уметь осуществлять над ним следующие операции:
1) get(\(a\), \(b\)) - узнать наибольший общий делитель чисел на отрезке от \(a\) до \(b\).
2) update(\(a\), \(b\), \(k\)) - для всех \(j\) от \(a\) до \(b\) увеличить \(j\)-е число на \(k \cdot (j - a + 1)\), т.е.
\(V_a += k\)
\(V_{a+1} += 2 \cdot k\)
...
\(V_b += (b - a + 1) \cdot k\)
Первая строка входного файла содержит два числа \(1 \le n \le 10^5\) - кол-во числе в массиве и \(1 \le q \le 10^5\) - кол-во запросов. Следующая строка содержит \(n\) чисел - массив \(V\) \(1 \le V_i \le 2 \cdot 10^8\).
Далее в \(q\) строках идет информация о запросах:
Каждый запрос get задается тремя числами 0 \(a\) \(b\)
Каждый запрос update задается четырьмя числами 1 \(a\) \(b\) \(k\) (\(1 \le k \le 2 \cdot 10^8\))
Для каждого запроса get выведите наибольший общий делитель чисел на отрезке от \(a\) до \(b\)
Подзадача 1(20 баллов) \(1 \le n \le 1000\), \(1 \le q \le 1000\)
Подзадача 2(20 баллов) нет запросов update
Подзадача 3(60 баллов) нет дополнительных ограничений
8 3 2 8 12 24 66 33 21 7 0 2 4 1 1 4 2 0 2 4
4 2