Вася пишет новую версию своего офисного пакета "Closed Office". Недавно он начал работу над редактором "Dword", входящим в состав пакета.
Последняя проблема, с которой столкнулся Вася --- размещение рисунков в документе. Он никак не может добиться стабильного отображения рисунков в тех местах, в которые он их помещает. Окончательно отчаявшись написать соответствующий модуль самостоятельно, Вася решил обратиться за помощью к вам. Напишите программу, которая будет осуществлять размещение документа на странице.
Документ в формате редактора "Dword" представляет собой последовательность абзацев. Каждый абзац представляет собой последовательность элементов – слов и рисунков. Элементы одного абзаца разделены пробелами и/или переводом строки. Абзацы разделены пустой строкой. Строка, состоящая только из пробелов, считается пустой.
Слово --- это последовательность символов, состоящая из букв латинского алфавита, цифр, и знаков препинания: ".", ",", ":", ";", "!", "?", "-", "'".
Рисунок описывается следующим образом: "(image
| Параметр | Описание |
| width | Целое положительное число – ширина рисунка в пикселях |
| height | Целое положительное число – высота рисунка в пикселях |
| layout | Одно из следующих значений: embedded (в тексте), surrounded (обтекание текстом), floating (свободное) – описывает расположение рисунка относительно текста |
Документ размещается на бесконечной вверх и вниз странице шириной \(w\) пикселей (разбиение на конечные по высоте страницы планируется в следующей версии редактора). Одна из точек на левой границе страницы условно считается точкой с ординатой равной нулю. Ордината увеличивается вниз.
Размещение документа происходит следующим образом. Абзацы размещаются по очереди. Первый абзац размещается так, что его верхняя граница имеет ординату 0.

Абзац размещается следующим образом. Элементы располагаются по строкам. Каждая строка исходно имеет высоту \(h\) пикселей. В процессе размещения рисунков высота строк может увеличиваться, и строки могут разбиваться рисунками на фрагменты.

Слова размещаются следующим образом. Считается, что каждый символ имеет ширину \(c\) пикселей. Перед каждым словом, кроме первого во фрагменте, ставится пробел шириной также в \(c\) пикселей. Если слово помещается в текущем фрагменте, то оно размещается на нем. Если слово не помещается в текущем фрагменте, то оно размещается в первом фрагменте текущей строки, расположенном правее текущего, в котором оно помещается. Если такого фрагмента нет, то начинается новая строка, и поиск подходящего фрагмента продолжается в ней. Слово всегда "прижимается" к верхней границе строки.
Размещение рисунка зависит от его расположения относительно текста.
Если расположение рисунка относительно текста установлено в "\(embedded\)", то он располагается так же, как слово, за тем исключением, что его ширина равна ширине, указанной в параметрах рисунка. Кроме того, если высота рисунка больше текущей высоты строки, то она увеличивается до высоты рисунка (при этом верхняя граница строки не перемещается, а смещается вниз нижняя граница). Если рисунок типа "\(embedded\)" не первый элемент во фрагменте, то перед ним ставится пробел шириной \(c\) пикселей. Рисунки типа "\(embedded\)" также прижимаются к верхней границе строки.
Если расположение рисунка относительно текста установлено в "\(surrounded\)", то рисунок размещается следующим образом. Сначала аналогично находится первый фрагмент, в котором рисунок помещается по ширине. При этом перед рисунком этого типа не ставится пробел, даже если это не первый элемент во фрагменте.
После этого рисунок размещается следующим образом: верхний край рисунка совпадает с верхней границей строки, в которой находится найденный фрагмент, а сам рисунок продолжается вниз. При этом строки, через которые он проходит, разбиваются им на фрагменты.
Если расположение рисунка относительно текста установлено в "\(floating\)", то рисунок размещается поверх текста и других рисунков и никак с ними не взаимодействует. В этом случае у рисунка есть два дополнительных параметра: "\(dx\)" и "\(dy\)" --- целые числа, задающие смещение в пикселях верхнего левого угла рисунка вправо и вниз, соответственно, относительно позиции, где находится верхний правый угол предыдущего слова или рисунка (или самой левой верхней точки первой строки абзаца, если рисунок --- первый элемент абзаца).
Если при размещении рисунка таким образом он выходит за левую границу страницы, то он смещается вправо, так, чтобы его левый край совпадал с левой границей страницы. Аналогично, если рисунок выходит за правую границу страницы, то он смещается влево, чтобы его правый край совпадал с правой границей страницы.
Верхняя граница следующего абзаца совпадает с более низкой точкой из нижней границы последней строки и самой нижней границы рисунков типа "\(surrounded\)" предыдущего абзаца.
По заданным \(w\), \(h\), \(c\) и документу найдите координаты верхних левых углов всех рисунков в документе.
В первой строке вводятся три целых числа: \(w\), \(h\) и \(c\) (\(1 \le w \le 1000\), \(1 \le h \le 50\), \(1 \le c \le w\)).
Далее следует документ. Размер входных данных не превышает \(1000\) байт. Гарантируется, что ширина любого слова и любого рисунка не превышает \(w\). Высота всех рисунков не превышает 1000. Относительное смещение всех рисунков типа "\(floating\)" не превышает \(1000\) по абсолютной величине.
Выведите по два числа для каждого рисунка --- координаты его верхнего левого угла. Выводите координаты рисунков в том порядке, в котором они встречаются во входных данных.
Рисунок к примеру
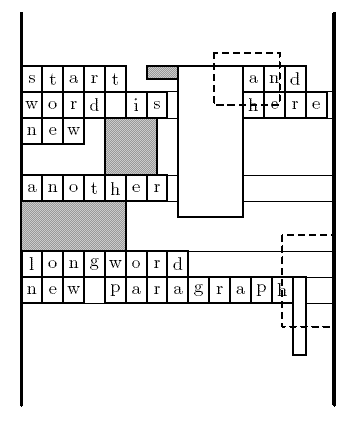
120 10 8 start (image layout=embedded width=12 height=5) (image layout=surrounded width=25 height=58) and word is (image layout=floating dx=18 dy=-15 width=25 height=20) here new (image layout=embedded width=20 height=22) another (image layout=embedded width=40 height=19) longword new paragraph (image layout=surrounded width=5 height=30) (image layout=floating width=20 height=35 dx=50 dy=-16)
48 0 60 0 74 -5 32 20 0 52 104 81 100 65
Вася написал на длинной полоске бумаги большое число и решил похвастаться своему старшему брату Пете этим достижением. Но только он вышел из комнаты, чтобы позвать брата, как его сестра Катя вбежала в комнату и разрезала полоску бумаги на несколько частей. В результате на каждой части оказалось одна или несколько идущих подряд цифр.
Теперь Вася не может вспомнить, какое именно число он написал. Только помнит, что оно было очень большое. Чтобы утешить младшего брата, Петя решил выяснить, какое максимальное число могло быть написано на полоске бумаги перед разрезанием. Помогите ему!
Входные данные состоят из одной или более строк, каждая из которых содержит последовательность цифр. Количество строк не превышает 100, каждая строка содержит от 1 до 100 цифр. Гарантируется, что хотя бы в одной строке первая цифра отлична от нуля.
Выведите одну строку – максимальное число, которое могло быть написано на полоске перед разрезанием.
2 20 004 66
66220004
3
3
Максимальное время работы на одном тесте: 2 секунды
Телевидение Флатландии готовится показать в вечернем эфире выступление одного известного политика. Поскольку политик известен своей несдержанностью, решено было написать специальную программу, которая вырезала бы из речи политика некоторые фразы, запуская в этот момент рекламу.
Поскольку ввести все неполиткорректные слова в программу представляется довольно сложным, решено было использовать эвристический алгоритм определения адекватности фразы.
Речь политика в реальном времени оцифровывается, распознается и подается на вход программе как последовательность фраз. Каждая фраза состоит из слов, записанных в одну строку. Слово представляет собой последовательность символов, ограниченную с обеих сторон границами фразы, пробелами или знаками препинания (символами «.», «!», «?», «:», «-», «,», «;», «(» или «)»).
Слово считается подозрительным, если в него входит не более трех различных букв (любой символ, кроме пробелов и знаков препинания считается буквой, большие и маленькие буквы считаются различными). Например, слова «дом», «мама» или «шалаш» являются подозрительными, а слова «привет», «Шалаш» или «hello» – нет.
Фраза считается подозрительной, если не менее половины слов в ней подозрительны (каждое вхождение слова во фразу считается отдельно).
Напишите программу, которая процензурирует речь политика, удалив из нее все подозрительные фразы.
Формат входных данных
Вводится не более 1000 фраз, каждая из которых представляет собой строку не длиннее 250 символов. Фраза содержит только символы с ASCII кодами от 32 до 255.
Формат выходных данных
Выведите все фразы из входных данных, которые не являются подозрительными. Фразы следует выводить в том же порядке, в котором они поступали на вход программы.
Примеры
| Входные данные | Выходные данные |
Наша система власти достаточно стабильна. | Наша система власти достаточно стабильна. |
Для идентификации ресурсов в сети Internet используются URL (Uniform Resource Locator). URL состоит из нескольких элементов: протокол, хост, порт, путь, файл и секция. Некоторые элементы URL могут быть опущены. Рассмотрим упрощенный формат URL:
[протокол://]хост[:порт][путь/[файл[#секция]]]
Заключенные в квадратные скобки элементы могут быть опущены, т.е. например, можно не указать протокол или секцию. Но, например, если указан файл, то обязательно должен быть указан путь. Регистр букв в элементах URL не важен.
Рассмотрим кратко все элементы URL:
*Протокол - это способ доступа к файлу, URL с разными протоколами и одинаковыми остальными элементами могут указывать на различные ресурсы.
*Хост и порт - это имя некоторого сервера в сети и способ доступа к нему (порт - натуральное число, не превосходящее 65535).
*Путь представляет собой путь к файлу, содержащему запрашиваемый ресурс, от некоторого каталога на сервере, который называется корневым. При этом для разделения имен каталогов используется символ "/". Путь, если он не пуст, всегда начинается с символа "/". Специальное обозначение '.' соответствует самому каталогу, '..' - родительскому каталогу.
*Файл - это файл, содержащий запрашиваемый ресурс.
Наконец, файл может быть разбит на секции каким либо способом и можно указать, к какой именно секции вы хотите обратиться.
Различные символы в URL могут быть заменены своими шестнадцатеричными ASCII кодами с помощью символа %, например a = %41, Z = %5A. В коде всегда используется ровно две шестнадцатеричные цифры.
Некоторые символы могут встречаться в элементах URL только как шестнадцатеричные коды - все символы, кроме букв латинского алфавита, цифр и символов "." и "-", а некоторые не могут встречаться вообще: "\", "#", "*", "@", "%", "?", ":", ",", а также символы с ASCII-кодом меньше %20. Символ "/" может встречаться в элементах URL только в пути для разделения входящих в него каталогов. Имя файла не может состоять только из точек.
Рассмотрим примеры URL:
http://neerc.ifmo.ru/school
ftp://somewhere.net:1234/pub/files/coolgame.zip
nobody.nowhere.net/some%20dir/some%20file#some%20info
Ваша цель в этой задаче - помочь разработчикам web-сервера. Для web-сервера отсутствующие части URL имеют следующие значения по умолчанию:

neerc.ifmo.ru
http://neerc.ifmo.ru:80/index.html#
Http://NEERC.IFMO.Ru/Dir/../././
Для разграничения доступа к ресурсам необходимо уметь определять, указывают ли два различных URL на один и тот же ресурс. Помогите разработчикам написать соответствующую проверку.
Входные данные состоят из двух строк, каждая из них содержит URL. Оба URL удовлетворяют формату, приведенному в условии этой задачи. Длина каждого URL не превосходит 200 символов. Гарантируется, что ни один из промежуточных каталогов на пути к ресурсу не лежит выше корневого каталога (т.е. не может встретиться, например, URL http://somewhere.com/../dir/index.html) а также, что имена всех каталогов состоят по крайней мере из одного символа (два символа "/" не могут идти подряд в любом месте, кроме как непосредственно после двоеточия после имени протокола).
Выведите YES, если оба URL, приведенные во входных данных, указывают на один и тот же ресурс, и NO в противном случае.
neerc.ifmo.ru neerc.ifmo.ru:80
YES
neerc.ifmo.ru NEERC.IFMO.RU
YES
abcdefghijklmnopqrstuvwxyz.com ABCDEFGHIJKLMNOPQRSTUVWXYZ.COM
YES
zzz.com zzz.net
NO
http://abcdefghijklmnopqrstuvwxyz.com ABCDEFGHIJKLMNOPQRSTUVWXYZ.COM
YES
hello%20world.com helloworld.com
NO
В теории кодирования часто используют беспрефиксные коды наборы слов, ни одно из которых не является префиксом (Слово α называется префиксом слова β, если α получается из β удалением нуля или более символов в конце. Например, слова, a, ab и aba являются префиксами слова aba) другого. Например, набор слов aba, aa и bac является беспрефиксным кодом, а набор abac, aba, ba нет, поскольку слово aba является префиксом слова abac.
Профессор Дешифро работает в лаборатории исследования бесполезной информации и изучает свое новое изобретение почти беспрефиксные коды. Набор слов называется почти беспрефиксным кодом уровня k, если наибольший общий префикс двух любых слов из набора не превышает по длине k. Например, набор abac, abс, ba является почти беспрефиксным кодом уровня 2, а набор abac , abab, ba нет, поскольку наибольший общий префикс слов abac и abab имеет длину 3.
Очередная задача, которую профессор Дешифро поставил своим лаборантам, заключается в следующем: по заданному набору слов и числу k требуется выбрать из заданных слов максимальный набор, который является почти беспрефиксным кодом уровня k. Вам, как младшему лаборанту, поручили написать соответствующую программу.
Первая строка входного файла содержит два целых числа: n и k количество слов в заданном наборе и уровень почти беспрефиксного кода, который требуется построить (1 ≤ n ≤ 100000, 0 ≤ k ≤ 200). Следующие n строк содержат по одному слову. Слова состоят из строчных букв латинского алфавита. Длина каждого слова от 1 до 200 символов. Суммарная длина всех слов не превышает 106. Все слова различны.
На первой строке выходного файла выведите одно число m - максимальное количество слов, которые можно выбрать из заданного набора, чтобы они образовывали почти беспрефиксный код уровня k. Следующие m строк должны содержать выбранные слова.
6 2 aba bacaba abacaba baca abac caba
3 aba baca caba